Dual Arc A770 and Ollama - impressions and a quick guide

I got a second Intel Arc A770 Limited Edition (16Gb) for my "local AI" server.
Got it from someone who was using it for gaming only for a year, so for a 300USD (30000 RUB) I got a:
- an original box
- a cable to control RGB lights
- a GPU

Before that also got a Asrcok Taichi X399 with Threadripper 1950x CPU for 350USD (35000 RUB) in pristine condition.
I decided to move my old-ish Ubuntu install from single GPU setup to the new motherboard and update Ollama afterwards to use Gemma3 and Qwen3, but I failed. After a 2+ hours of tinkering with old Ubuntu 22 I decided to backup all my models and user data to the USB thumb drive and do a fresh install.
Well, I installed my Ubuntu Server 24.10, because that's what Intel website recommends, downloaded Ollama-IPEX portable install thingy, and started the server. No dice - my GPUs were not detected at all. Solved by adding
export OLLAMA_INTEL_GPU=trueto the start-ollama.sh script in the folder. After that, all two GPUs were detected, but I was getting SIGBUS errors on loading models into VRAM. I stumbled upon this Github discussion. Using scripts were not possible due to how I run Ollama-IPEX (without Python environment), so turning off Secure Boot and enabling Above 4G Decoding and ReBAR in motherboard UEFI settings fixed this issue.
I started phi4:latest, and it was... fine - the model was split between 2 GPUs, 5.5Gb VRAM in each GPU. I was getting abysmal 10.5 tokens/second (more on that later)!
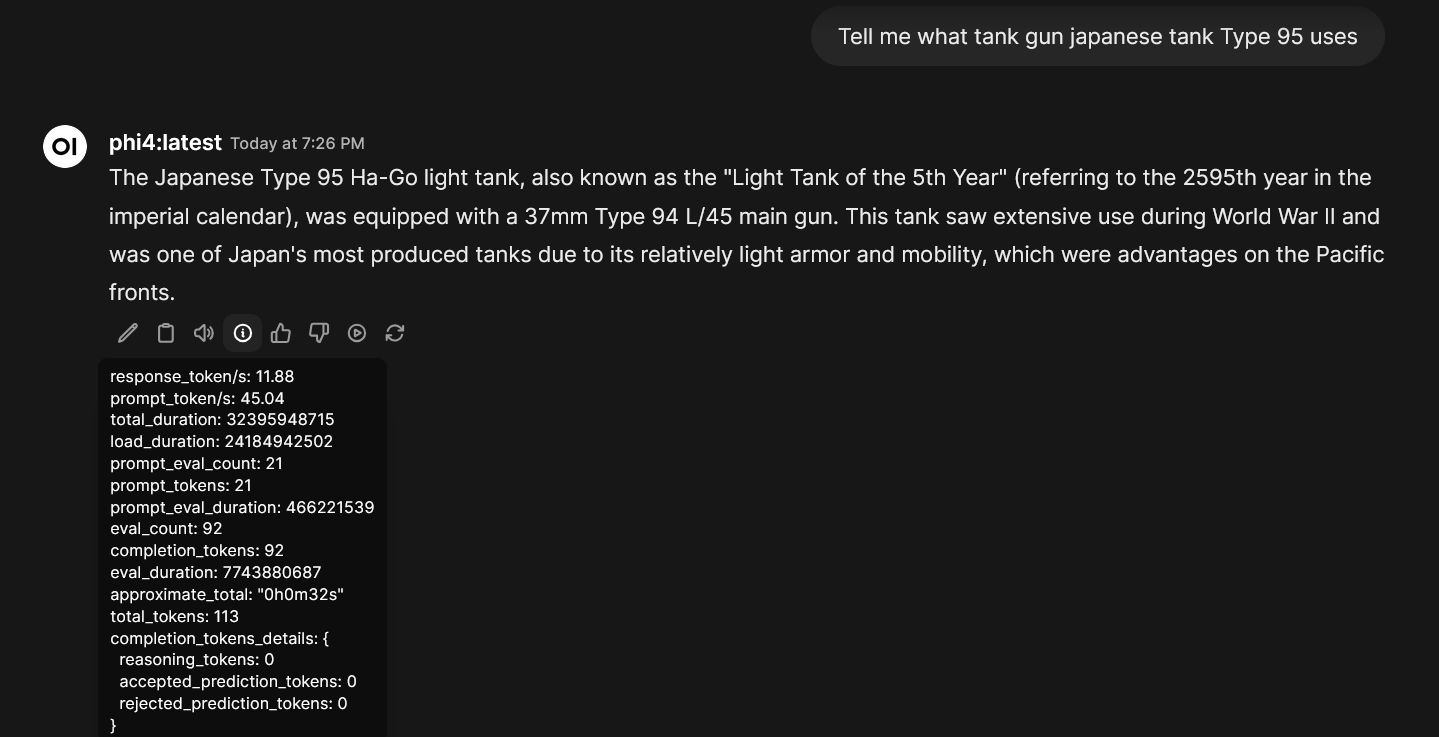
Also Gemma3 was not starting at all - that's because at the May 2025 Ollama-IPEX (Intel GPUs) were not really compatible with that model, AFAIK.
Some old models were not launching due to lack of libur_loader.0.10 library in
/opt/intel/oneapi/2025.1/lib/Well, apart from slow-ish text generation everything was fine. Exept for big models, like Qwen3:30B - I was getting 6 tokens/second with web search added via searXNG!!
Anyway, I spend like 8-10 hours tinkering with drivers - compiled libur_loader from scratch, installed oneAPI-2025 drivers. Even tried to move to the vLLM, but a single run of
sudo apt update -y && sudo apt upgrade -y
sudo rebootgot me 19 tokens/s in phi4:latest (was 11 t/s):

...and 10 tokens/s in Qwen3:30B (was 5 t/s).
To sum things up, with:
- two Arc A770 Limited Edition with 16Gb VRAM for 600USD
- Asrock Taichi X399 and a Threadripper 1950x (16c/32t) for 350USD
- Also reused a PSU from my gaming rig with two 8pin+6pin power connectors and a 4pin+8pin CPU power connectors, AData 8200 SSD for storage and stuff
I got a working, though not really fast, Open Web UI with the power to use 32b models, also started a searXNG service for more relevant answers.
Be careful though, there GPUs run hot, even with vapor chamber as main cooling - backplate was hot (like, 65 degrees Celsius hot) to the touch, but the fans were not spinning at idle. For some reason, I have no info on any temperatures of a GPU core, memory and all that stuff via
xpu-smi stats -d 0
xpu-smi stats -d 1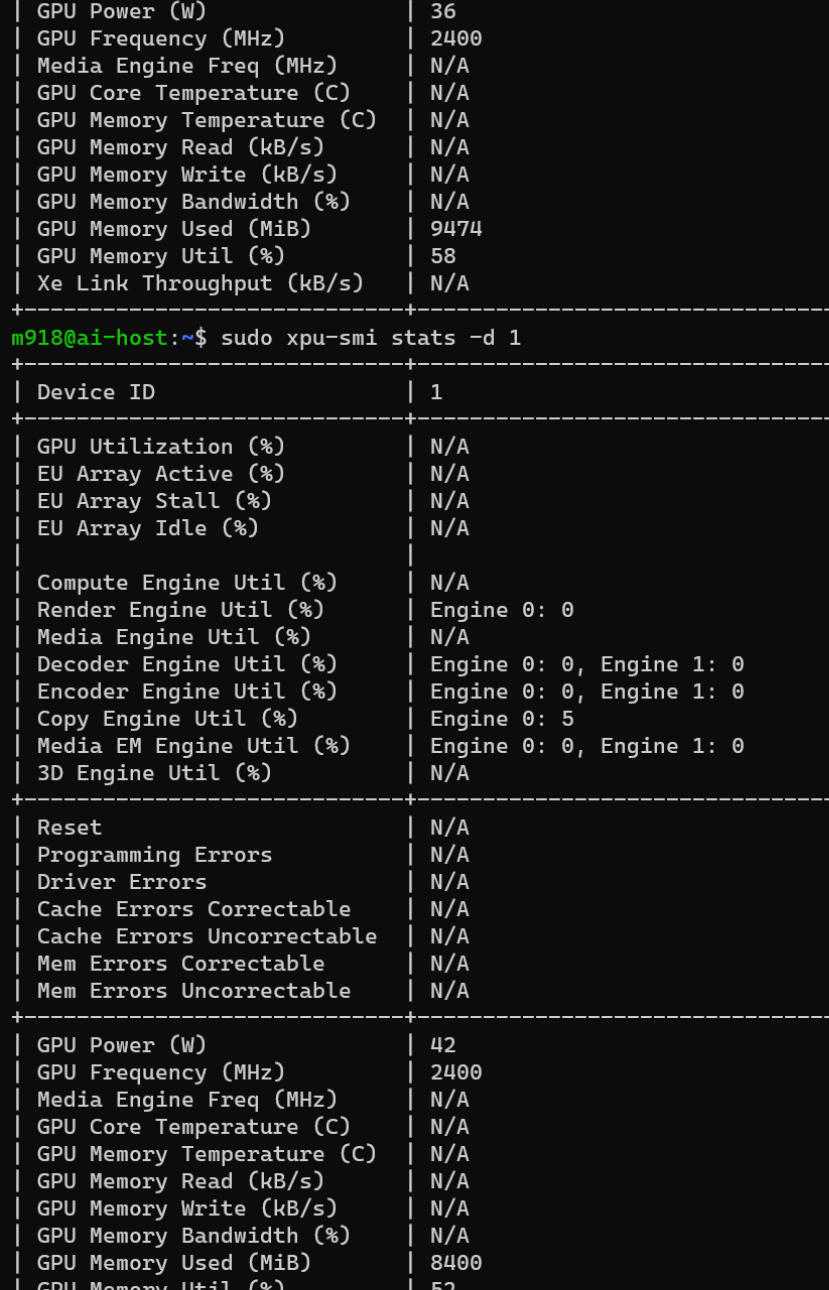
It was kinda... fun, I guess?
P.S.:
my start-ollama.sh looks like this:
#!/bin/bash
export OLLAMA_NUM_GPU=999
export no_proxy=localhost,127.0.0.1
export ZES_ENABLE_SYSMAN=1
#super important for Intel GPUs:
export OLLAMA_INTEL_GPU=true
export SYCL_CACHE_PERSISTENT=1
export OLLAMA_KEEP_ALIVE=1h
#Default value is 0, which means "use all GPUs"
#export OLLAMA_NUM_PARALLEL=1
#Introduces instability
#export OLLAMA_FLASH_ATTENTION=1
#no effect on performance
export OLLAMA_SCHED_SPREAD=true
export OLLAMA_MAX_LOADED_MODELS=2
#no effect on performance
export OLLAMA_NEW_ENGINE=true
#no effect on performance
export OLLAMA_SCHED_SPREAD=true
#no effect on performance
#export OLLAMA_GPUMEMORY=36000MB # vram limit
# [optional] under most circumstances, the following environment variable may improve performance, but sometimes this may also cause performance degradation
export SYCL_PI_LEVEL_ZERO_USE_IMMEDIATE_COMMANDLISTS=1
export ONEAPI_DEVICE_SELECTOR="level_zero:0;level_zero:1"
/home/m918/ollama-ipex-llm-2.3.0b20250429-ubuntu/ollama serve