Installing Ollama on Ubuntu & Arc A770 GPU

So... After Wolfgang's video on selfhosted LLMs I decided to at least try to deploy Ollama at home.
Since I had only mITX gaming PC with 6600XT and no free time for games, I decided to buy Intel Arc A770 for 270USD - had a good offer on almost unused GPU - and sell my old AMD Radeon 6600XT for 160USD. I had no idea if it would work at all though.
 intel-analytics
intel-analyticsAnyway, all I had to do is:
- Install Ubuntu 24 with Gnome as a Desktop Environment (not like I care for desktop flavor though)
- Follow instructions on https://github.com/intel-analytics/ipex-llm, specifically these guides:
- Use following guide to install GPU drivers.
Go for option 1 (for Intel Core CPUs or multiple Arc GPUs).
I could not get intel-i915-dkms and intel-fw-gpu to work though, and kept running into errors via apt installer (something-something "error code 10" on every install of the intel-i915-dkms via apt package manager). - After installing OneAPI drivers, create Python environment via conda app.
This is really important, don't skip it. Copying and pasting commands to the command (almost) mindlessly would probably work - it worked for me.
You don't have to go past "Verify Installation" part on that page. - Complete the next part: install llama-cpp. It's pretty straightforward - create Python environment via conda app, download packages, initialize llama-cpp in a separate folder. You can skip step 3 on that page.
- Try to run Ollama instance via this guide.
Pretty straightforward, just copy-paste commands to the command line.
I had some issues with getting LLM to work via my GPU, here are some thoughts:
- You absolutely have to run Ollama via ./ollama serve command inside conda environment:
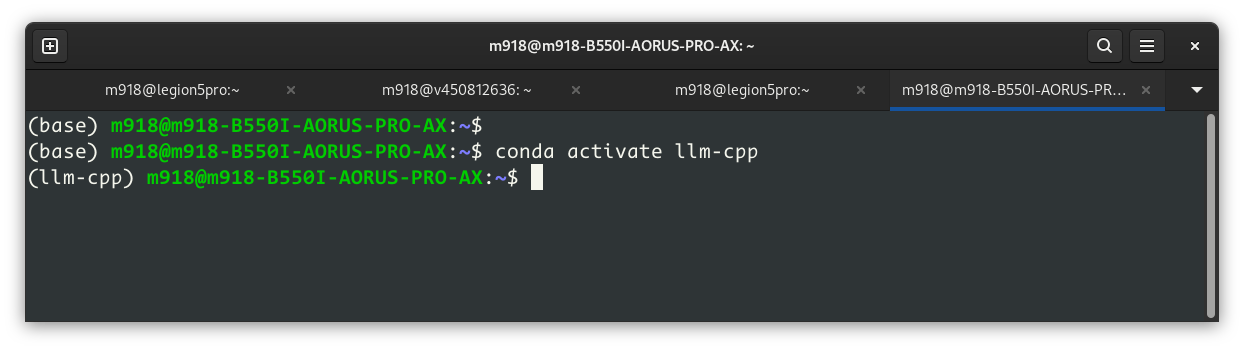
- Why? Because you have all necessary packages installed in the llm-cpp environment, not in the base one.
- I also had trouble with Ollama and core dumps on the very start of the generation via CLI or Web UI, does not matter. I fixed it via removing intel-i915-dkms and intel-fw-gpu packages entirely - it seems that Ubuntu 24 already had them installed (I have no idea why, though, but I had GPU acceleration on a fresh install).
- If you have no /opt/intel/ folder, you have missed something while installing GPU drivers.
If and only if you have everything working - you asked LLM something and got an answer, then all you have to do is to install Open WebUI.
It's simple, just keep in mind that npm i command may stuck on installing packages - use VPN to get past restrictions.
You might want to create systemd service for Ollama & Open WebUI.
Create a following file in /etc/systemd/system/ folder, name it ollama.service file (don't forget to change User, Group and ExecStart lines):
[Unit]
Description=Ollama Server with custom environment variables
[Service]
User=<yourUser>
Group=<yourGroup>
ExecStart=/home/<yourUser>/ollama/startup.sh
Environment="OLLAMA_NUM_GPU=999"
Environment="no_proxy=localhost,127.0.0.1"
Environment="ZES_ENABLE_SYSMAN=1"
Environment="SYCL_CACHE_PERSISTENT=1"
Environment="SYCL_PI_LEVEL_ZERO_USE_IMMEDIATE_COMMANDLISTS=1"
Environment="ONEAPI_DEVICE_SELECTOR=level_zero:0"
StandardOutput=syslog
StandardError=syslog
SyslogIdentifier=ollama
[Install]
WantedBy=multi-user.target
systemd service file
The startup.sh file is simple:
#!/bin/sh
conda activate llm-cpp
# Execute the ollama serve command
# Update this path to where your ollama executable is located
exec "/home/<yourUser>/ollama/ollama" serve
A simple startup script
Check if it works by stopping all running Ollama instances (if you had any), then execute:
# Reload systemd files
sudo systemctl daemon-reload
# Start ollama.service
sudo systemctl start ollama.service
#Check ollama.service status
systemctl statu ollama.service
If you see something like this,

then enable service via
sudo systemctl enable ollama.serviceDo the same for the Open WebUI:
[Unit]
Description=Open WebUI Server
[Service]
ExecStart=/home/<yourUser>/open-webui/backend/start.sh
StandardOutput=syslog
StandardError=syslog
SyslogIdentifier=open-webui
[Install]
WantedBy=multi-user.target
systemd service file
Edit (4 Dec 2024):
Performance data for 1 Arc A770 16Gb (FE) with qwen2.5-coder:14b and mistral-nemo:12b models for period from 3 December to 4 December is:
ollama[43348]: INFO [print_timings] prompt eval time = 296.42 ms / 24 tokens ( 12.35 ms per token, 80.97 tokens per second)
ollama[43348]: INFO [print_timings] generation eval time = 9470.45 ms / 327 runs ( 28.96 ms per token, 34.53 tokens per second)
ollama[43348]: INFO [print_timings] total time = 9766.87 ms
ollama[43348]: INFO [print_timings] prompt eval time = 802.10 ms / 133 tokens ( 6.03 ms per token, 165.82 tokens per second)
ollama[43348]: INFO [print_timings] generation eval time = 264.94 ms / 10 runs ( 26.49 ms per token, 37.74 tokens per second)
ollama[43348]: INFO [print_timings] total time = 1067.03 ms
ollama[43885]: INFO [print_timings] prompt eval time = 317.30 ms / 15 tokens ( 21.15 ms per token, 47.27 tokens per second)
ollama[43885]: INFO [print_timings] generation eval time = 21722.09 ms / 734 runs ( 29.59 ms per token, 33.79 tokens per second)
ollama[43885]: INFO [print_timings] total time = 22039.38 ms
^^^ Data for mistral-nemo:12b model...........................
vvv Data for qwen2.5-coder:14b model..........................
ollama[43885]: INFO [print_timings] prompt eval time = 750.78 ms / 124 tokens ( 6.05 ms per token, 165.16 tokens per second)
ollama[43885]: INFO [print_timings] generation eval time = 206.89 ms / 8 runs ( 25.86 ms per token, 38.67 tokens per second)
ollama[43885]: INFO [print_timings] total time = 957.67 ms
ollama[43927]: INFO [print_timings] prompt eval time = 1621.91 ms / 772 tokens ( 2.10 ms per token, 475.98 tokens per second)
ollama[43927]: INFO [print_timings] generation eval time = 41054.60 ms / 705 runs ( 58.23 ms per token, 17.17 tokens per second)
ollama[43927]: INFO [print_timings] total time = 42676.51 ms
ollama[43927]: INFO [print_timings] prompt eval time = 718.24 ms / 1521 tokens ( 0.47 ms per token, 2117.69 tokens per second)
ollama[43927]: INFO [print_timings] generation eval time = 29125.68 ms / 494 runs ( 58.96 ms per token, 16.96 tokens per second)
ollama[43927]: INFO [print_timings] total time = 29843.92 ms
ollama[43968]: INFO [print_timings] prompt eval time = 463.09 ms / 45 tokens ( 10.29 ms per token, 97.17 tokens per second)
ollama[43968]: INFO [print_timings] generation eval time = 24489.37 ms / 424 runs ( 57.76 ms per token, 17.31 tokens per second)
ollama[43968]: INFO [print_timings] total time = 24952.47 ms
ollama[44013]: INFO [print_timings] prompt eval time = 3024.17 ms / 2042 tokens ( 1.48 ms per token, 675.23 tokens per second)
ollama[44013]: INFO [print_timings] generation eval time = 23908.29 ms / 423 runs ( 56.52 ms per token, 17.69 tokens per second)
ollama[44013]: INFO [print_timings] total time = 26932.46 ms
ollama[44013]: INFO [print_timings] prompt eval time = 59.98 ms / 42 tokens ( 1.43 ms per token, 700.19 tokens per second)
ollama[44013]: INFO [print_timings] generation eval time = 60943.08 ms / 1083 runs ( 56.27 ms per token, 17.77 tokens per second)
ollama[44013]: INFO [print_timings] total time = 61003.07 ms
ollama[44013]: INFO [print_timings] prompt eval time = 516.60 ms / 135 tokens ( 3.83 ms per token, 261.32 tokens per second)
ollama[44013]: INFO [print_timings] generation eval time = 389.73 ms / 8 runs ( 48.72 ms per token, 20.53 tokens per second)
ollama[44013]: INFO [print_timings] total time = 906.33 ms
ollama[47369]: INFO [print_timings] prompt eval time = 640.97 ms / 71 tokens ( 9.03 ms per token, 110.77 tokens per second)
ollama[47369]: INFO [print_timings] generation eval time = 20868.29 ms / 375 runs ( 55.65 ms per token, 17.97 tokens per second)
ollama[47369]: INFO [print_timings] total time = 21509.25 ms
ollama[47369]: INFO [print_timings] prompt eval time = 667.05 ms / 164 tokens ( 4.07 ms per token, 245.86 tokens per second)
ollama[47369]: INFO [print_timings] generation eval time = 388.67 ms / 8 runs ( 48.58 ms per token, 20.58 tokens per second)
ollama[47369]: INFO [print_timings] total time = 1055.71 ms
ollama[47369]: INFO [print_timings] prompt eval time = 607.01 ms / 63 tokens ( 9.64 ms per token, 103.79 tokens per second)
ollama[47369]: INFO [print_timings] generation eval time = 13614.29 ms / 246 runs ( 55.34 ms per token, 18.07 tokens per second)
ollama[47369]: INFO [print_timings] total time = 14221.30 ms
ollama[47369]: INFO [print_timings] prompt eval time = 461.76 ms / 156 tokens ( 2.96 ms per token, 337.84 tokens per second)
ollama[47369]: INFO [print_timings] generation eval time = 564.63 ms / 11 runs ( 51.33 ms per token, 19.48 tokens per second)
ollama[47369]: INFO [print_timings] total time = 1026.39 ms
ollama[50378]: INFO [print_timings] prompt eval time = 430.86 ms / 54 tokens ( 7.98 ms per token, 125.33 tokens per second)
ollama[50378]: INFO [print_timings] generation eval time = 20482.94 ms / 367 runs ( 55.81 ms per token, 17.92 tokens per second)
ollama[50378]: INFO [print_timings] total time = 20913.80 ms
ollama[50378]: INFO [print_timings] prompt eval time = 733.11 ms / 147 tokens ( 4.99 ms per token, 200.52 tokens per second)
ollama[50378]: INFO [print_timings] generation eval time = 445.60 ms / 9 runs ( 49.51 ms per token, 20.20 tokens per second)
ollama[50378]: INFO [print_timings] total time = 1178.71 ms
Energy consumption (measured with TP-Link Tapo P115):
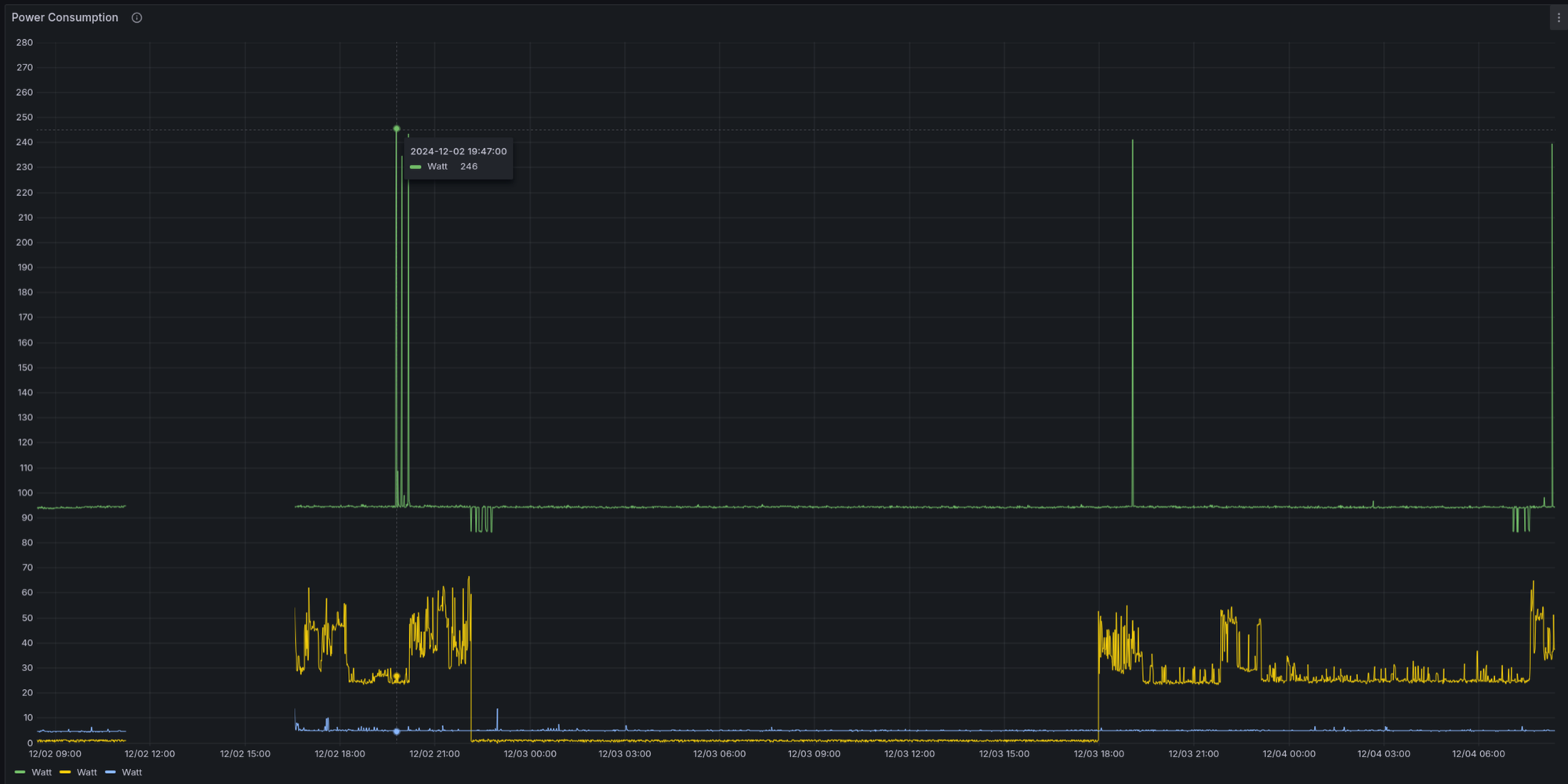
~250W load, 90W idle (my C-States are messed up, I'll fix that soon).